


量子位 | 公众号 QbitAI
一篇被Yann LeCun转发的ICML 2025研究给了多模态大模型当头一棒——
大部分AI在复杂任务上表现很好,但在人类从小就会的基础认知能力上却很拉垮。
研究者建了测评题库CoreCognition,覆盖在人类婴幼儿阶段即出现的12种核心认知能力(如客体永恒、视角采择、直觉物理、知觉恒常等),用来对模型进行系统性测试。
在CoreCognition基准的1503道“经典发展心理学测验”上,230个主流模型系统暴露出对世界常识的“核心知识盲区”。
在归一化准确率对比中,多模态大模型在基础核心认知能力上普遍落后,差距往往达到两位数,即便规模更大也难以弥补。
这是否意味着MLLM(多模态大模型)的先天认知结构中,缺少那些支撑早期人类学习的基础知识机制?
也就是说,它们是否缺乏“core knowledge”(核心认知能力)?
构建CoreCognition Benchmark

来自加州大学圣地亚哥分校、约翰霍普金斯大学、埃默里大学、北卡罗来纳大学教堂山分校、斯坦福大学、卡内基梅隆大学等机构的研究人员,花费一年时间构造并开源了业界首个核心认知基准CoreCognition。
基准围绕发展心理学与皮亚杰分层框架,覆盖从连续性到机械推理12 项核心认知概念,共1503道多模态题目,每类≥95例,含图像与视频。
研究团队在设计题目时遵循以下高标准:
- 判别性强
不具备目标核心知识的模型在逻辑上更易选择错误选项。
- 最小混淆
题目尽量仅依赖待测概念完成推理,剔除与其他核心知识或外部能力的耦合,避免跨概念干扰。
不具备目标核心知识的模型在逻辑上更易选择错误选项。
题目尽量仅依赖待测概念完成推理,剔除与其他核心知识或外部能力的耦合,避免跨概念干扰。
- 无文本捷径
所有题目必须联合利用图像与文本才能得出正确答案。
所有题目必须联合利用图像与文本才能得出正确答案。
所有数据由12位具备认知科学、计算机科学或统计学背景的高年级本科或研究生协作完成标注与审核,经过两轮交叉验证和Amazon Mechanical Turk人工校验。
干预测试揭示“假理解”陷阱
为了进一步验证模型是否真的掌握核心概念,研究团队提出了Concept Hacking(概念干预) 方法:通过构造“对照组”(control)与“干预组”(manipulated),故意在测试任务中反转与核心知识相关的关键特征,但保持其余细节一致,检测模型是否真正理解概念还是走捷径。
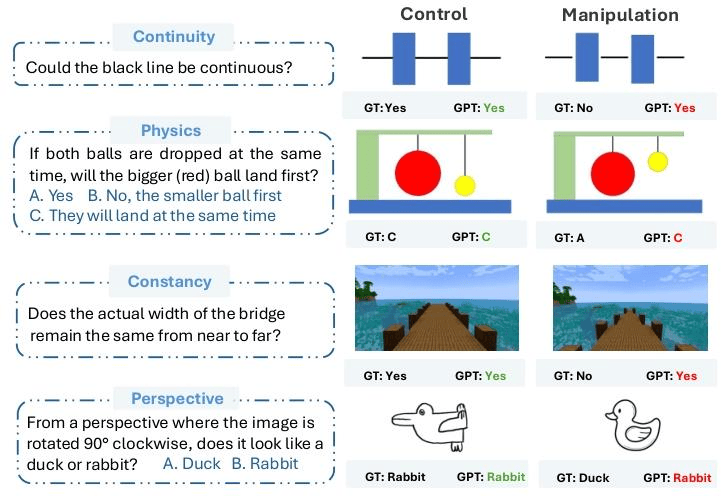
例如其中的Intuitive Physics测试:
- 原版题
同时释放两颗小球,哪一个会先落地?考察基础直觉物理(相同释放高度、忽略空气阻力时,自由落体等时到地)。
- 孪生版
保持大小不变,但改变释放高度,用以检验模型是否真正依据高度差/落地时间推断,而非套用“同时落地”的固定模板。
- 人类表现
两题均能作对,能根据高度改变及时更新判断。
- 模型表现
原题作对(选C),孪生版仍沿用旧模式选C,直接翻车——暴露出对表面模板的依赖,而非对落体规律的真实理解。
同时释放两颗小球,哪一个会先落地?考察基础直觉物理(相同释放高度、忽略空气阻力时,自由落体等时到地)。
保持大小不变,但改变释放高度,用以检验模型是否真正依据高度差/落地时间推断,而非套用“同时落地”的固定模板。
两题均能作对,能根据高度改变及时更新判断。
原题作对(选C),孪生版仍沿用旧模式选C,直接翻车——暴露出对表面模板的依赖,而非对落体规律的真实理解。
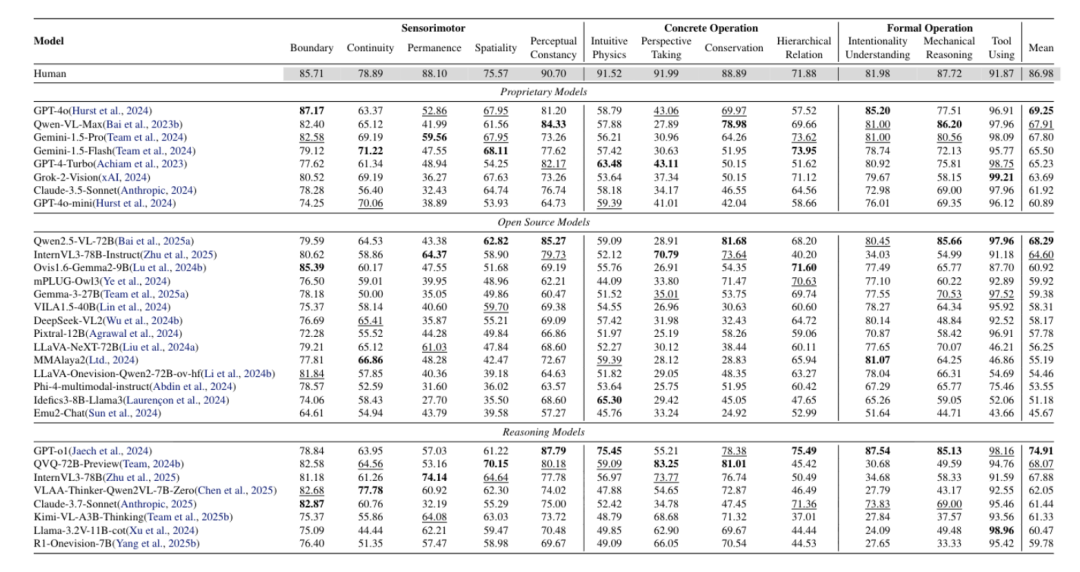
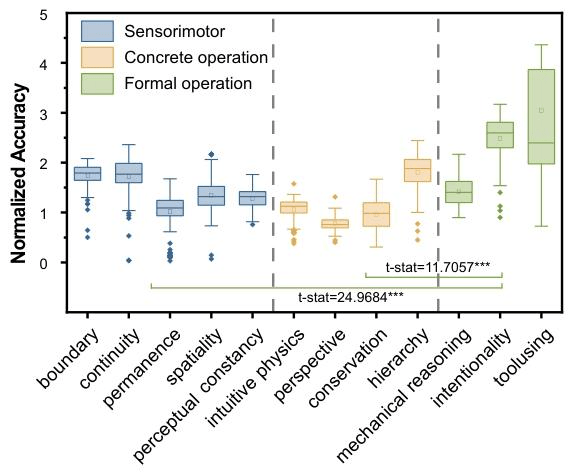
一、在与人类早期认知直接相关的低层能力(如边界感、连续性、客体永恒、空间性、视角采择等)上,模型显著落后于高层能力(如意向理解、工具使用、机械推理),与人类各层稳定高分的模式明显不同。这表明
当前MLLMs在人类早期即具备的基础“核心知识”上存在系统性短板。
二、关联性矩阵显示,高层能力族内关联较强,底层能力Permanence/Spatiality/Continuity与高层能力相关性普遍偏弱。说明模型缺乏人类由低到高的脚手架式认知发展结构,模型的高级感知与推理并不是建立在基础的认知能力上的。这也能解释为什么模型出现鲁棒性缺陷。

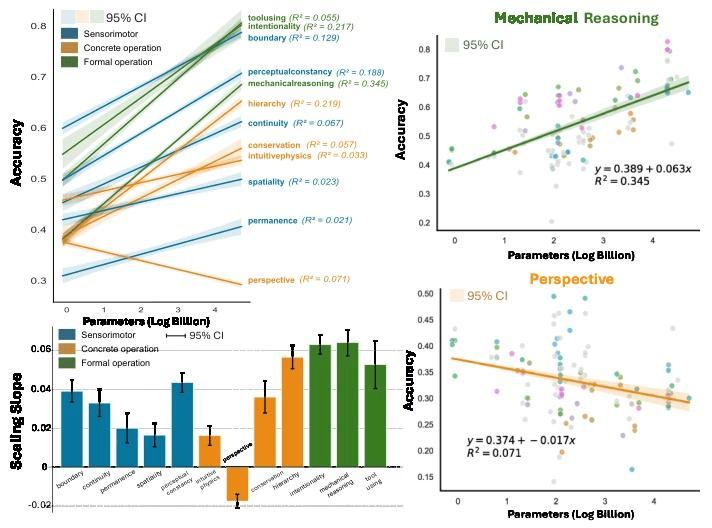
三、研究团队将三阶段12个核心能力的得分与26个公开基准做相关性分析,结果表明除Perspective和Intuitive Physics外,大多数核心能力与公开基准(除ChartQA)及高层能力显著正相关。这表明核心知识越强,上层任务越稳。而Perspective和Intuitive Physics能力作为人类高级推理的基础展现出的低相关性,与我们之前在关系矩阵里看到的模式一致,这正是现有模型核心知识缺陷的直接证据。
四、基于230个模型拟合“规模—表现”的回归斜率显示,低层能力随规模提升改善显著更少或几乎不变;其中Perspective-taking甚至出现反向规模效应(模型越大越差)。增加模型规模主要利好高层能力,对低层核心能力帮助有限甚至为负。
五、Concept Hacking实验结果显示,大模型相较小模型整体并未取得提升,部分情形甚至更差。这说明单靠扩规模不足以消除对捷径的依赖,也难以获得稳健的核心知识。直观上,模型并非“越大越懂”,而是越大越善于投机。
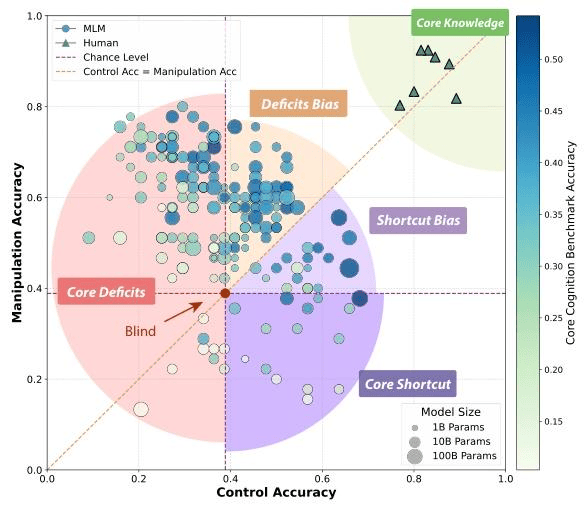
结合结果图中的信息,模型可归纳为四类:
- 核心知识型
控制题与操纵题均表现良好(接近人类水平,但样本占比极少),说明具备稳健的核心概念理解与迁移。
- 捷径依赖型
控制题得分高、操纵题显著下降,提示主要依赖表面线索或训练相似性,缺乏对概念要素的因果把握。
- 核心缺陷型
控制题即低于或接近偶然水平,操纵题亦无稳定收益,反映基础“核心知识”不足。
- 偶然型
控制题与操纵题均近似随机波动,整体不可依赖(更多体现噪声与运气)。
控制题与操纵题均表现良好(接近人类水平,但样本占比极少),说明具备稳健的核心概念理解与迁移。
控制题得分高、操纵题显著下降,提示主要依赖表面线索或训练相似性,缺乏对概念要素的因果把握。
控制题即低于或接近偶然水平,操纵题亦无稳定收益,反映基础“核心知识”不足。
控制题与操纵题均近似随机波动,整体不可依赖(更多体现噪声与运气)。
认知指令带来短期增益,但难以弥补底层缺口。
对比推理模型与其对应非推理版本模型性能显示,推理模型多数核心能力任务未见显著提升,症结不在“会不会用推理”,而在底层表征是否具备,即预训练阶段对核心知识的覆盖与结构化不足。
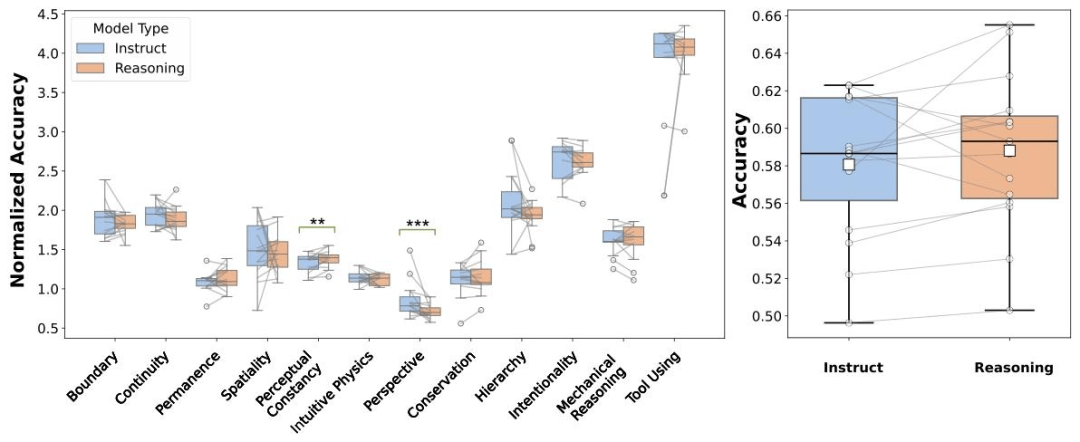
与此同时,研究团队发现,引入认知指令(在题目前明确提示相关概念,如perspective taking)可带来约6%的即刻增益,提示模型内部可能分布式存有相关线索,但缺少有效的检索与调用机制。
然而,此类做法在真实场景中可获得性与可用性受限,实际应用往往无法提供如此明确的概念标签来引导模型。
在引人注目的“能写会画”之外,真正的智能首先取决于对世界最朴素规则的把握。
这项研究说明:参数堆叠并不等于理解,地基是否扎实才是关键。
与其一味追求“更大、更强”,不如换个起点:先把核心知识补齐,让模型学会在变化、多样与噪声中保持一致的常识判断与因果直觉。
简单说就是:先长地基,再长楼层;规模是加法,核心认知是乘法。
论文地址:https://arxiv.org/abs/2410.10855
Website:https://grow-ai-like-a-child.github.io/core-knowledge/
Dataset:https://huggingface.co/datasets/williamium/CoreCognition
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






